分布式事务方案
问题引出
在微服务架构中,随着服务的逐步拆分,数据库私有已经成为共识,这也导致所面临的分布式事务问题成为微服务落地过程中一个非常难以逾越的障碍,但是目前尚没有一个完整通用的解决方案。为了保证分布式事务一致性目前业内成熟的解决方案有
强一致分布式事务方案:其中包括两段式提交协议 2PC、三段式提交协议 3PC。
最终一致分布式事务方案:其中包括事件通知模式(本地异步事件服务模式、外部事件服务模式、事务消息模式、最大努力通知模式)、事务补偿模式(Saga、TCC)。
各模式分析
本地事务
在分析各模式之前,先回顾一下传统的单机本机事务。
传统单机应用使用一个 RDBMS 作为数据源。应用开启事务,进行 CRUD,提交或回滚事务,统统发生在本地事务中,由资源管理器(RM)直接提供事务支持。数据的一致性在一个本地事务中得到保证。
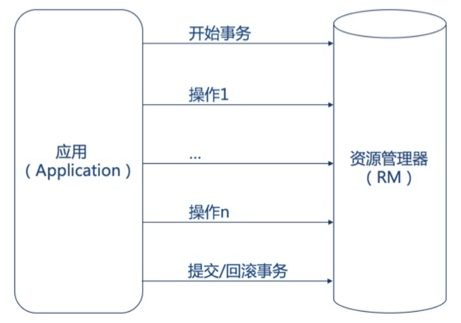
强一致分布式事务方案
两阶段提交协议(2PC)
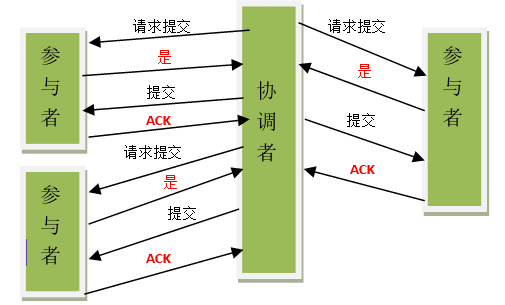
显然随着服务的逐步拆分,各个服务均有自己的数据库,这个时候本地事务已经无法满足数据一致性的要求。由于多个数据源的同时访问,事务需要跨多个数据源管理。于是参考设计本地事务的思想,前人很自然研究出了两阶段提交(2PC)这种分布式事务模式。两阶段提交分为准备阶段和提交阶段。
两阶段提交-commit
两阶段提交-rollback
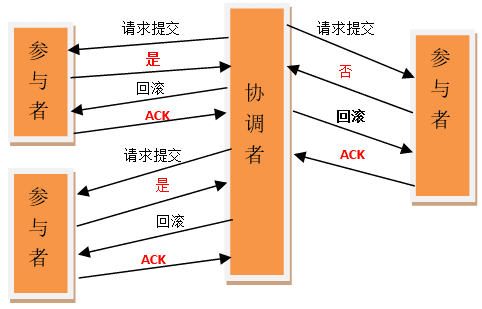
2PC 看着挺美好,但其实是存在缺陷的:
2PC 在执行过程中可能发生协调者或者参与者突然宕机的情况,在不同时期宕机可能有不同的现象。
情况一:协调者挂了,参与者没挂
这种情况其实比较好解决,只要找一个协调者的替代者。当他成为新的协调者的时候,询问所有参与者的最后那条事务的执行情况,他就可以知道是应该做什么样的操作了。所以,这种情况不会导致数据不一致。
情况二:参与者挂了,协调者没挂
这种情况其实也比较好解决。如果协调者挂了。那么之后的事情有两种情况:
- 第一个是挂了就挂了,没有再恢复。那就挂了呗,反正不会导致数据一致性问题。
- 第二个是挂了之后又恢复了,这时如果他有未执行完的事务操作,直接取消掉,然后询问协调者目前我应该怎么做,协调者就会比对自己的事务执行记录和该参与者的事务执行记录,告诉他应该怎么做来保持数据的一致性。
情况三:参与者挂了,协调者也挂了 这种情况比较复杂,我们分情况讨论。
协调者和参与者在第一阶段挂了。
由于这时还没有执行 commit 操作,新选出来的协调者可以询问各个参与者的情况,再决定是进行 commit 还是 roolback。因为还没有 commit,所以不会导致数据一致性问题。
第二阶段协调者和参与者挂了,挂了的这个参与者在挂之前并没有接收到协调者的指令,或者接收到指令之后还没来的及做 commit 或者 roolback 操作。 这种情况下,当新的协调者被选出来之后,他同样是询问所有的参与者的情况。只要有机器执行了 abort(roolback)操作或者第一阶段返回的信息是 No 的话,那就直接执行 roolback 操作。如果没有人执行 abort 操作,但是有机器执行了 commit 操作,那么就直接执行 commit 操作。这样,当挂掉的参与者恢复之后,只要按照协调者的指示进行事务的 commit 还是 roolback 操作就可以了。因为挂掉的机器并没有做 commit 或者 roolback 操作,而没有挂掉的机器们和新的协调者又执行了同样的操作,那么这种情况不会导致数据不一致现象。
- 第二阶段协调者和参与者挂了,挂了的这个参与者在挂之前已经执行了操作。但是由于他挂了,没有人知道他执行了什么操作。
这种情况下,新的协调者被选出来之后,如果他想负起协调者的责任的话他就只能按照之前那种情况来执行 commit 或者 roolback 操作。这样新的协调者和所有没挂掉的参与者就保持了数据的一致性,我们假定他们执行了 commit。但是,这个时候,那个挂掉的参与者恢复了怎么办,因为他之前已经执行完了之前的事务,如果他执行的是 commit 那还好,和其他的机器保持一致了,万一他执行的是 roolback 操作那?这不就导致数据的不一致性了么?虽然这个时候可以再通过手段让他和协调者通信,再想办法把数据搞成一致的,但是,这段时间内他的数据状态已经是不一致的了!
所以,2PC 协议中,如果出现协调者和参与者都挂了的情况,有可能导致数据不一致。
三段式提交协议(3PC)
为了解决上述问题,前人在 2PC 基础上又研究出 3PC 的方案。
3PC 最关键要解决的就是协调者和参与者同时挂掉的问题,所以 3PC 把 2PC 的准备阶段再次一分为二,这样三阶段提交就有 CanCommit、PreCommit、DoCommit 三个阶段。在第一阶段,只是询问所有参与者是否可可以执行事务操作,并不在本阶段执行事务操作。当协调者收到所有的参与者都返回 YES 时,在第二阶段才执行事务操作,然后在第三阶段在执行 commit 或者 rollback。
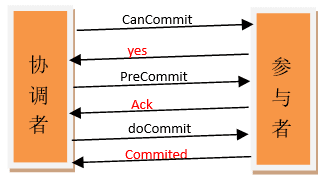
3PC 相对 2PC 的优点:
直接分析协调者和参与者都挂的情况。
- 第二阶段协调者和参与者挂了,挂了的这个参与者在挂之前已经执行了操作。但是由于他挂了,没有人知道他执行了什么操作。
这种情况下,当新的协调者被选出来之后,他同样是询问所有的参与者的情况来觉得是 commit 还是 roolback。这看上去和二阶段提交一样啊?他是怎么解决一致性问题的呢?
看上去和二阶段提交的那种数据不一致的情况的现象是一样的,但仔细分析所有参与者的状态的话就会发现其实并不一样。我们假设挂掉的那台参与者执行的操作是 commit。那么其他没挂的操作者的状态应该是什么?他们的状态要么是 prepare-commit 要么是 commit。因为 3PC 的第三阶段一旦有机器执行了 commit,那必然第一阶段大家都是同意 commit。所以,这时,新选举出来的协调者一旦发现未挂掉的参与者中有人处于 commit 状态或者是 prepare-commit 的话,那就执行 commit 操作。否则就执行 rollback 操作。这样挂掉的参与者恢复之后就能和其他机器保持数据一致性了。(为了简单的让大家理解,笔者这里简化了新选举出来的协调者执行操作的具体细节,真实情况比我描述的要复杂)
简单概括一下就是,如果挂掉的那台机器已经执行了 commit,那么协调者可以从所有未挂掉的参与者的状态中分析出来,并执行 commit。如果挂掉的那个参与者执行了 rollback,那么协调者和其他的参与者执行的肯定也是 rollback 操作。
所以,再多引入一个阶段之后,3PC 解决了 2PC 中存在的那种由于协调者和参与者同时挂掉有可能导致的数据一致性问题。
3PC 也不是完美的,同样存在问题:
在 doCommit 阶段,如果参与者无法及时接收到来自协调者的 doCommit 或者 rebort 请求时,会在等待超时之后,会继续进行事务的提交。
所以,由于网络原因,协调者发送的 abort 响应没有及时被参与者接收到,那么参与者在等待超时之后执行了 commit 操作。这样就和其他接到 abort 命令并执行回滚的参与者之间存在数据不一致的情况。
最终一致分布式事务方案
尽管 2PC/3PC 存在一些问题,但其实是通过提升服务运营能力部分克服问题,那是不是 2PC/3PC 就可以满足微服务场景下分布式事务的需求了呢?答案是否定的,原因有三点:
- 由于微服务间无法直接进行数据访问,微服务间互相调用通常通过 RPC(Dubbo)或 Http API(Spring Cloud)进行,所以已经无法使用 TM 统一管理微服务的 RM。
- 不同的微服务使用的数据源类型可能完全不同,如果微服务使用了 NoSQL 之类不支持事务的数据库,则事务根本无从谈起。
- 即使微服务使用的数据源都支持事务,那么如果使用一个大事务将许多微服务的事务管理起来,这个大事务维持的时间,将比本地事务长几个数量级。如此长时间的事务及跨服务的事务,将为产生很多锁及数据不可用,严重影响系统性能。
由此可见,传统的分布式事务已经无法满足微服务架构下的事务管理需求。那么,既然无法满足传统的 ACID 事务,在微服务下的事务管理必然要遵循新的法则--BASE 理论。
BASE 理论由 eBay 的架构师 Dan Pritchett 提出,BASE 理论是对 CAP 理论的延伸,核心思想是即使无法做到强一致性,应用应该可以采用合适的方式达到最终一致性。BASE 是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency)。
- 基本可用:指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
- 软状态:允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。
- 最终一致性:最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
BASE 中的最终一致性是对于微服务下的事务管理的根本要求,即虽然基于微服务的事务管理无法达到强一致性,但必须保证最终一致性,这就是所说的柔性事务。
实现事务最终一致性的方案主要有事件通知模式、事务补偿模式两种。
事件通知方案
事件通知模式的设计理念比较容易理解,即是主服务完成后将结果通过事件(常常是消息队列)传递给从服务,从服务在接受到消息后进行消费,完成业务,从而达到主服务与从服务间的消息一致性。
设计理念很简单,那是不是真的很简单呢?小白可能很简单地想到以下方案:
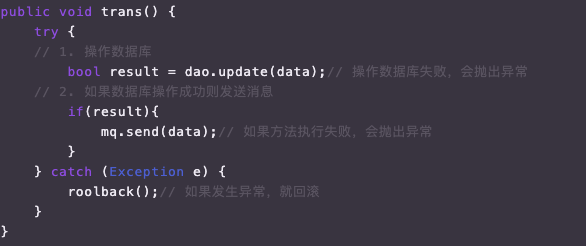
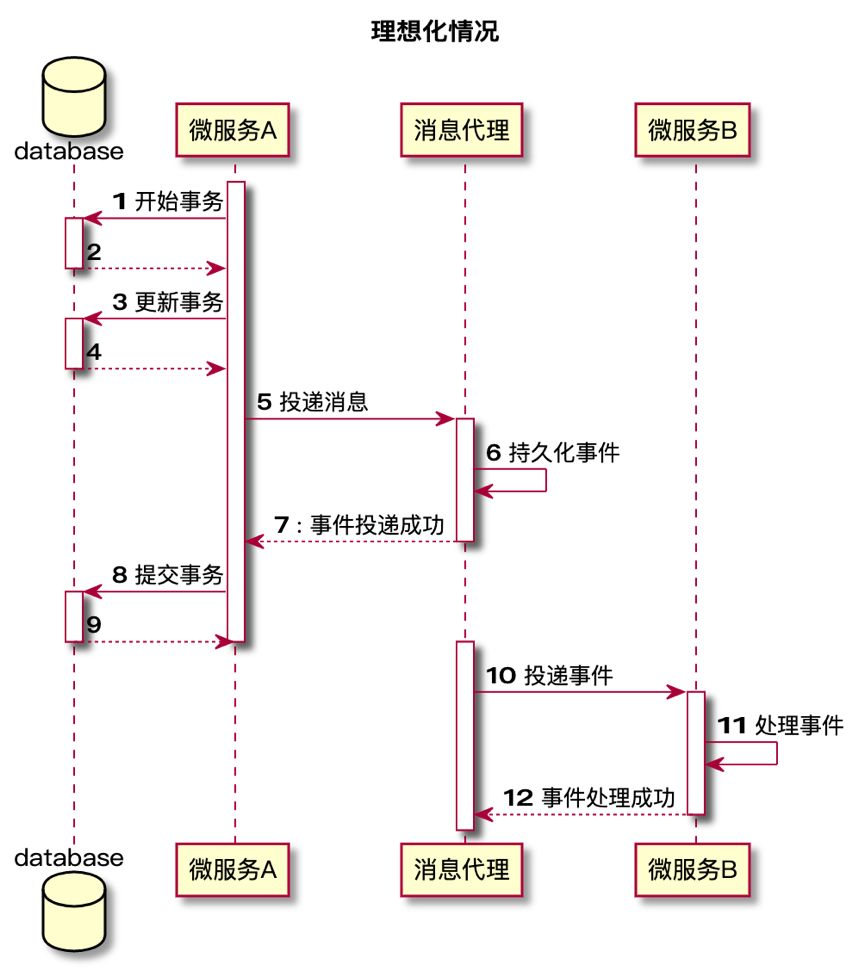
上面的逻辑看上去天衣无缝,如果数据库操作失败则直接退出,不发送消息;如果发送消息失败,则数据库回滚;如果数据库操作成功且消息发送成功,则业务成功,消息发送给下游消费。然后仔细思考后,这种同步消息通知有两个问题:
- 在微服务的架构下,有可能出现网络 IO 问题或者服务器宕机的问题,如果这些问题出现在时序图的第 7 步,使得消息投递后无法正常通知主服务(网络问题),或无法继续提交事务(宕机),那么主服务将会认为消息投递失败,会滚主服务业务,然而实际上消息已经被从服务消费,那么就会造成主服务和从服务的数据不一致。具体场景可见下面两张时序图。
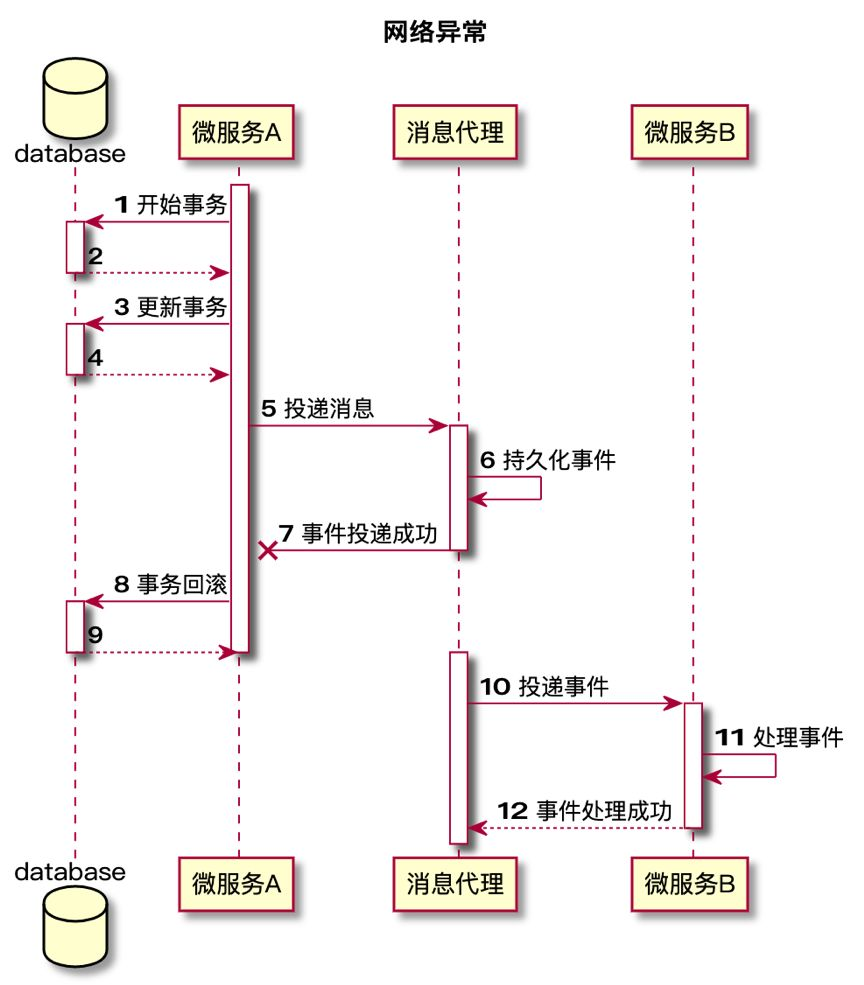
- 事件服务(在这里就是消息服务)与业务过于耦合,如果消息服务不可用,会导致业务不可用。应该将事件服务与业务解耦,独立出来异步执行,或者在业务执行后先尝试发送一次消息,如果消息发送失败,则降级为异步发送。
-
本地异步事件服务模式
为了解决上述同步事件中描述的同步事件的问题,异步事件通知模式被发展了出来,既业务服务和事件服务解耦,事件异步进行,由单独的事件服务保证事件的可靠投递。
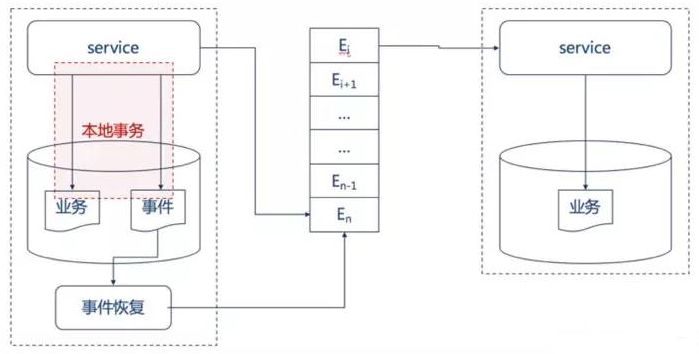
当业务执行时,在同一个本地事务中将事件写入本地事件表,同时投递该事件,如果事件投递成功,则将该事件从事件表中删除。如果投递失败,则由定时任务异步统一地处理投递失败的事件,进行重新投递,直到事件被正确投递,并将事件从事件表中删除。这个在本服务内部的定时任务一般叫它本地事件服务。这种方式最大可能地保证了事件投递的实效性,并且当第一次投递失败后,也能使用本地事件服务保证事件至少被投递一次。
-
外部异步事件服务模式
上述使用本地事件服务保证可靠事件通知的方式也有它的不足之处,那便是业务仍旧与事件服务有一定耦合(第一次同步投递时),更为严重的是,本地事务需要负责额外的事件表的操作,为数据库带来了压力,在高并发的场景,由于每一个业务操作就要产生相应的事件表操作,几乎将数据库的可用吞吐量砍了一半,这无疑是无法接受的。正是因为这样的原因,可靠事件通知模式进一步地发展-外部事件服务出现在了人们的眼中。
外部事件服务在本地事件服务的基础上更进了一步,将事件服务独立出主业务服务,主业务服务不在对事件服务有任何强依赖。
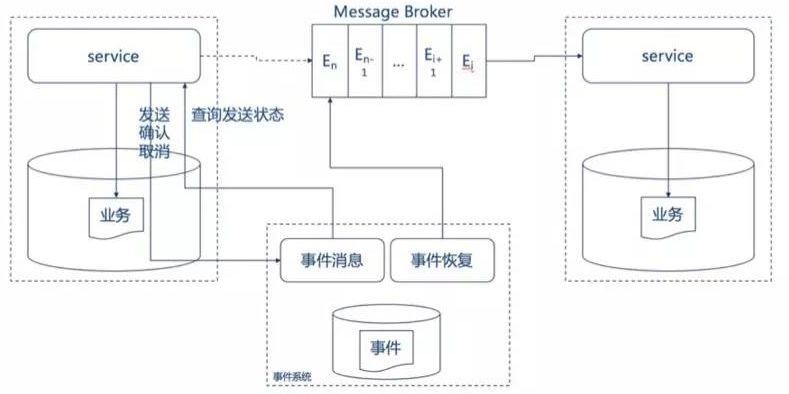
业务服务在提交前,向事件服务发送事件,事件服务只记录事件,并不发送。业务服务在提交或回滚后通知事件服务,事件服务发送事件或者删除事件。不用担心业务系统在提交或者会滚后宕机而无法发送确认事件给事件服务,因为事件服务会定时获取所有仍未发送的事件并且向业务系统查询,根据业务系统的返回来决定发送或者删除该事件。
外部事件虽然能够将业务系统和事件系统解耦,但是也带来了额外的工作量:外部事件服务比起本地事件服务来说多了两次网络通信开销(提交前、提交/回滚后),同时也需要业务系统提供单独的查询接口给事件系统用来判断未发送事件的状态。
-
MQ 事务消息模式
上述外部事件服务虽然解耦得比较成功,但其实还是需要自行开发一个独立的事件服务系统的,比较麻烦。其实还有更优雅地方案:事务消息模式。假如使用的 MQ 本身支持事务消息,这样业务应用就能以某种方式确保消息正确投递到 MQ。这个方案的代表是 RocketMQ。
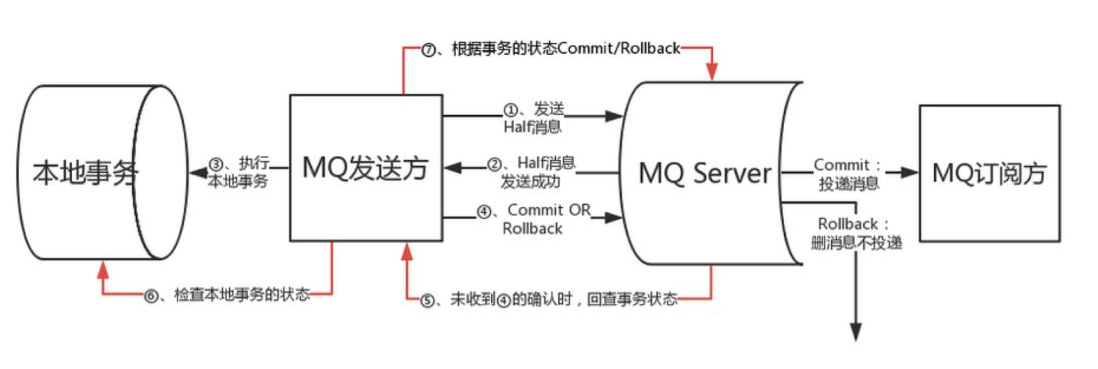
在 RocketMQ 这个方案里,事务消息作为一种异步确保型事务, 将两个事务分支通过 MQ 进行异步解耦,RocketMQ 事务消息的设计流程同样借鉴了两阶段提交理论,整体交互流程如下图所示:
- 事务发起方首先发送 prepare 消息到 MQ。
- 在发送 prepare 消息成功后执行本地事务。
- 根据本地事务执行结果返回 commit 或者是 rollback。
- 如果消息是 rollback,MQ 将删除该 prepare 消息不进行下发,如果是 commit 消息,MQ 将会把这个消息发送给 consumer 端。
- 如果执行本地事务过程中,执行端挂掉,或者超时,MQ 将会不停的询问其同组的其他 producer 来获取状态。
- Consumer 端的消费成功机制有 MQ 保证。
这里浏览下 RocketMQ 这种方案的代码:
TransactionProducer1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35public class TransactionProducer { public static void main(String[] args) throws MQClientException, InterruptedException { TransactionListener transactionListener = new TransactionListenerImpl(); TransactionMQProducer producer = new TransactionMQProducer("please_rename_unique_group_name"); ExecutorService executorService = new ThreadPoolExecutor(2, 5, 100, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(2000), new ThreadFactory() { @Override public Thread newThread(Runnable r) { Thread thread = new Thread(r); thread.setName("client-transaction-msg-check-thread"); return thread; } }); producer.setNamesrvAddr("10.10.15.246:9876;10.10.15.247:9876"); producer.setExecutorService(executorService); producer.setTransactionListener(transactionListener); producer.start(); String[] tags = new String[] {"TagA", "TagB", "TagC", "TagD", "TagE"}; for (int i = 0; i < 10; i++) { try { Message msg = new Message("TranTest", tags[i % tags.length], "KEY" + i, ("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)); SendResult sendResult = producer.sendMessageInTransaction(msg, null); System.out.printf("%s%n", sendResult); Thread.sleep(10); } catch (MQClientException | UnsupportedEncodingException e) { e.printStackTrace(); } } for (int i = 0; i < 100000; i++) { Thread.sleep(1000); } producer.shutdown(); } }TransactionListener1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24public class TransactionListenerImpl implements TransactionListener { private AtomicInteger transactionIndex = new AtomicInteger(0); private ConcurrentHashMap<String, Integer> localTrans = new ConcurrentHashMap<>(); public LocalTransactionState executeLocalTransaction(Message msg, Object arg) { int value = transactionIndex.getAndIncrement(); int status = value % 3; localTrans.put(msg.getTransactionId(), status); return LocalTransactionState.UNKNOW; } public LocalTransactionState checkLocalTransaction(MessageExt msg) { Integer status = localTrans.get(msg.getTransactionId()); if (null != status) { switch (status) { case 0: return LocalTransactionState.UNKNOW; case 1: return LocalTransactionState.COMMIT_MESSAGE; case 2: return LocalTransactionState.ROLLBACK_MESSAGE; } } return LocalTransactionState.COMMIT_MESSAGE; } }如果从代码的角度,可以看到在 RocketMQ 这个方案里,生产者 TransactionProducer 涉及到 2 个角色:本地事务执行器(代码中的 TransactionListenerImpl 的 executeLocalTransaction 方法)、服务器回查客户端 Listener(代码中 TransactionListenerImpl 的 checkLocalTransaction 方法)。
如果事务消息发送到 MQ 上后,会回调本地事务执行器;但是此时事务消息是 prepare 状态,对消费者还不可见,需要本地事务执行器返回 RMQ 一个确认消息。只有当确认完之后,才会将消息的状态由消费端不可见的 prepare 状态更新为消费者端可见的 commied 状态,如果本地事务执行器返回的是 rollbak,则 RMQ 直接删除该 prepare 状态的消息。
为了处理由于异常情况导致 RMQ 收不到本地事务执行器的确认消息的问题,RMQ 会通过服务器回查客户端 Listener 接口反查 prepare 状态事务消息最终应该的状态,从而将消息由消费端不可见的 prepare 状态更新为消费者端可见的 commied 状态或直接删除 prepare 状态的消息。
这里想到一个问题,为啥只有 RocketMQ 实现了事务消息的功能,其它 MQ 基本都没有实现这个功能。对于分布事务场景来说,这个功能不香吗?
其实业界各种 MQ 均有各自的适用场景,很多通用性 MQ 关注点是消息的高效流转,如果加上事务消息这一特性会导致 MQ 的性能打一些折扣。而解决消息的可靠投递并不一定需要使用事务消息方案,采用上面介绍的两种方法也可以。一句话,技术上并不是一定要追求架构的最优,还是要考虑综合效能。
-
事件最大努力通知
上面说到的 3 种模式,均可以保证事件消息可靠地投递到下游服务那儿去。但有些场景是允许一定程度地丢消息的。于是就发展出事件最大努力通知模式。最大努力通知型的特点是,业务服务在提交事务后,进行有限次数(设置最大次数限制)的消息发送,比如发送三次消息,若三次消息发送都失败,则不予继续发送。所以有可能导致消息的丢失。同时,主业务方需要提供查询接口给从业务服务,用来恢复丢失消息。最大努力通知型对于时效性保证比较差(既可能会出现较长时间的软状态),所以对于数据一致性的时效性要求比较高的系统无法使用。这种模式通常使用在不同业务平台服务或者对于第三方业务服务的通知,如银行通知、商户通知等。
事件通知模式要注意的点: 通过上面的描述,我们知道只要是使用事件通知模式,那么消费端收到的消息就有可能是重复的。那么就需要消费端保证同一条事件不会重复被消费,简而言之就是保证事件消费的幂等性。
如果事件本身是具备幂等性的状态型事件,如订单状态的通知(已下单、已支付、已发货等),则需要判断事件的顺序。一般通过时间戳来判断,既消费过了新的消息后,当接受到老的消息直接丢弃不予消费。如果无法提供全局时间戳,则应考虑使用全局统一的序列号。
对于不具备幂等性的事件,一般是动作行为事件,如扣款 100,存款 200,则应该将事件 ID 及事件结果持久化,在消费事件前查询事件 ID,若已经消费则直接返回执行结果;若是新消息,则执行,并存储执行结果。
-
事务补偿方案
除了事件通知模式外,事务补偿模式也可以实现事务的最终一致性。
补偿模式比起事件通知模式最大的不同是,补偿模式的上游服务依赖于下游服务的运行结果,而事件通知模式上游服务不依赖于下游服务的运行结果。
-
Saga 模式
Saga 是一种纯业务补偿模式,其设计理念为,业务在调用的时候正常提交,当一个服务失败的时候,所有其依赖的上游服务都进行业务补偿操作。
业务补偿模式要求每个服务都提供补偿接口,且这种补偿一般来说是不完全补偿,既即使进行了补偿操作,那条取消的火车票记录还是一直存在数据库中可以被追踪(一般是有相信的状态字段“已取消”作为标记),毕竟已经提交的线上数据一般是不能进行物理删除的。
业务补偿模式最大的缺点是软状态的时间比较长,既数据一致性的时效性很低,多个服务常常可能处于数据不一致的情况。
这种方案我以前在项目中深入实践中,可以看看这些文章:servicecomb-saga 开发实战、servicecomb-saga 源码解读。
-
TCC 模式
TCC 模式是一种优化了的业务补偿模式,它可以做到完全补偿,既进行补偿后不留下补偿的纪录,就好像什么事情都没有发生过一样。同时,TCC 的软状态时间很短,原因是因为 TCC 是一种两阶段型模式,只有在所有的服务的第一阶段(try)都成功的时候才进行第二阶段确认(Confirm)操作,否则进行补偿(Cancel)操作,而在 try 阶段是不会进行真正的业务处理的。
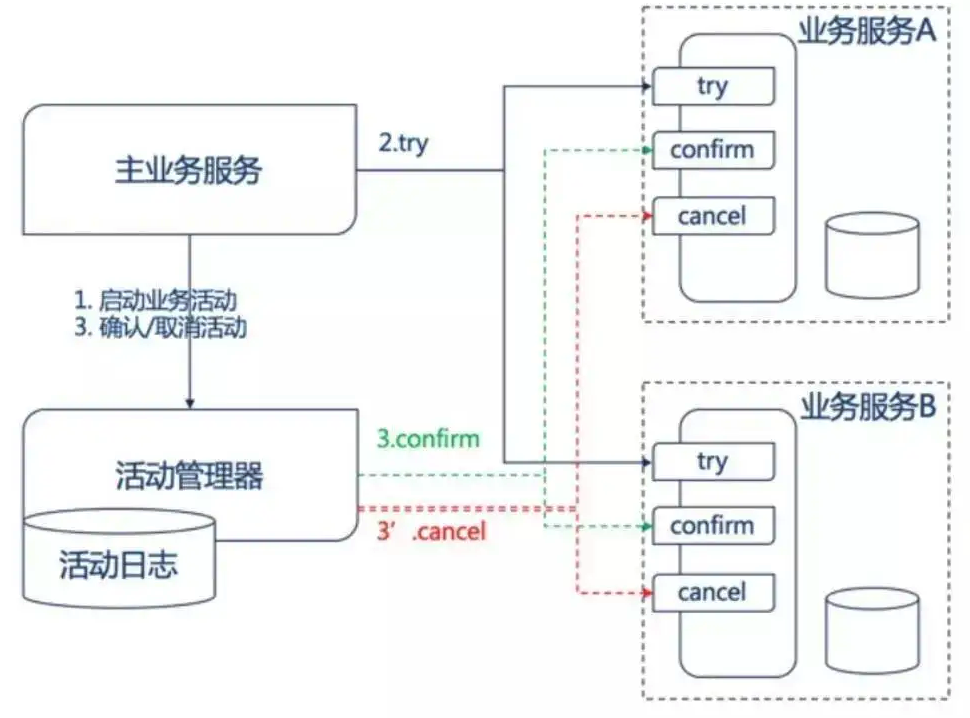
TCC 模式的具体流程为两个阶段:
- Try,业务服务完成所有的业务检查,预留必需的业务资源
- 如果 Try 在所有服务中都成功,那么执行 Confirm 操作,Confirm 操作不做任何的业务检查(因为 try 中已经做过),只是用 Try 阶段预留的业务资源进行业务处理;否则进行 Cancel 操作,Cancel 操作释放 Try 阶段预留的业务资源。
TCC 模式跟纯业务补偿模式相比,需要每个服务都需要实现 Confirm 和 Cancel 两个接口,因此落地实施上比纯业务补偿模式复杂一些,但好处是数据一致的实时性高,因此其在很多金融、电商场景中大量采用。
在事务补偿方案中,由于上游服务依赖于下游服务的结果,考虑到上下游服务间网络有可能是不稳定的,因此业务接口、补偿接口(Saga 模式中)和 Try 接口、Confirm 接口、Cancel 接口(TCC 模式中)均有可能会被多次调用,因此这些接口在实现时需要考虑幂等性。幂等性的实现方式可以是:
-
通过唯一键值做处理,即每次调用的时候传入唯一键值,通过唯一键值判断业务是否被操作,如果已被操作,则不再重复操作
-
通过状态机处理,给业务数据设置状态,通过业务状态判断是否需要重复执行
最终一致分布式方案对比
最终一致分布式方案如此之多,如何选择呢?其实还是要根据具体的业务场景。
| 类型 | 模式 | 数据一致性的实时性 | 开发成本 | 上游服务是否依赖下游服务结果 | 事件消息发送链路 | 业务耦合事件发送 | 绑定 MQ 特性 |
|---|---|---|---|---|---|---|---|
| 事件通知 | 本地异步事件服务模式 | 高 | 高 | 不依赖 | 短 | 高 | 否 |
| 事件通知 | 外部异步事件服务模式 | 高 | 高 | 不依赖 | 长 | 低 | 否 |
| 事件通知 | MQ 事务消息模式 | 高 | 低 | 不依赖 | 中 | 低 | 是 |
| 事件通知 | 事件最大努力通知模式 | 低 | 低 | 不依赖 | 短 | 高 | 否 |
| 事务补偿 | Saga 纯业务补偿模式 | 低 | 低 | 依赖 | - | - | - |
| 事务补偿 | TCC 业务补偿模式 | 高 | 高 | 依赖 | - | - | - |
各个方案均有优缺点,按照业务场景及开发团队的能力水平选择一种合适的方案即可。